defget(self, key: int) -> int: if key in self.hashmap: # 如果已经在链表中了,把它移到末尾(变成最新访问的) self.move_node_to_tail(key) res = self.hashmap.get(key, -1) if res == -1: return res #返回 -1 (未找到) else: return res.value #返回值
defput(self, key: int, value: int) -> None: if key in self.hashmap: # 如果key本身已经在哈希表中了就不需要在链表中加入新的节点 # 但是需要更新字典该值对应节点的value self.hashmap[key].value = value # 之后将该节点移到末尾 self.move_node_to_tail(key) else:#插入之前要判断容量够不够 iflen(self.hashmap) == self.capacity: #容量不够了,删! # 去掉哈希表对应项 self.hashmap.pop(self.head.next.key) # 去掉最久没有被访问过的节点,即头节点之后的节点 self.head.next = self.head.next.next self.head.next.prev = self.head #容量够的情况下: # 如果不在的话就插入new节点到尾节点前 new = ListNode(key, value) self.hashmap[key] = new new.prev = self.tail.prev new.next = self.tail self.tail.prev.next = new self.tail.prev = new
while l1: stack1.append(l1.val) l1 = l1.next while l2: stack2.append(l2.val) l2 = l2.next
ans = 0# 当前轮结果 add_num = 0# 向前进位 mod_num = 0# 余数——>存进链表的数字 head = None# 初始空链表
while stack1 or stack2 or add_num: # 存在两个栈空了,但还有进位没加进链表里 if stack1: a = stack1.pop() else: a = 0 if stack2: b = stack2.pop() else: b = 0 ans = (a + b) + add_num # 需要加上,上一轮进位 add_num = ans // 10# 向前进位 mod_num = ans % 10# 余数——>存进链表的数字 node = ListNode(mod_num) node.next = head head = node return head
# test l1 = ListNode(7) l1.next = ListNode(2) l1.next.next = ListNode(4) l1.next.next.next = ListNode(3) l2 = ListNode(5) l2.next = ListNode(6) l2.next.next = ListNode(4) p = addTwoNumbers(l1, l2) while p: print(p.val) p = p.next
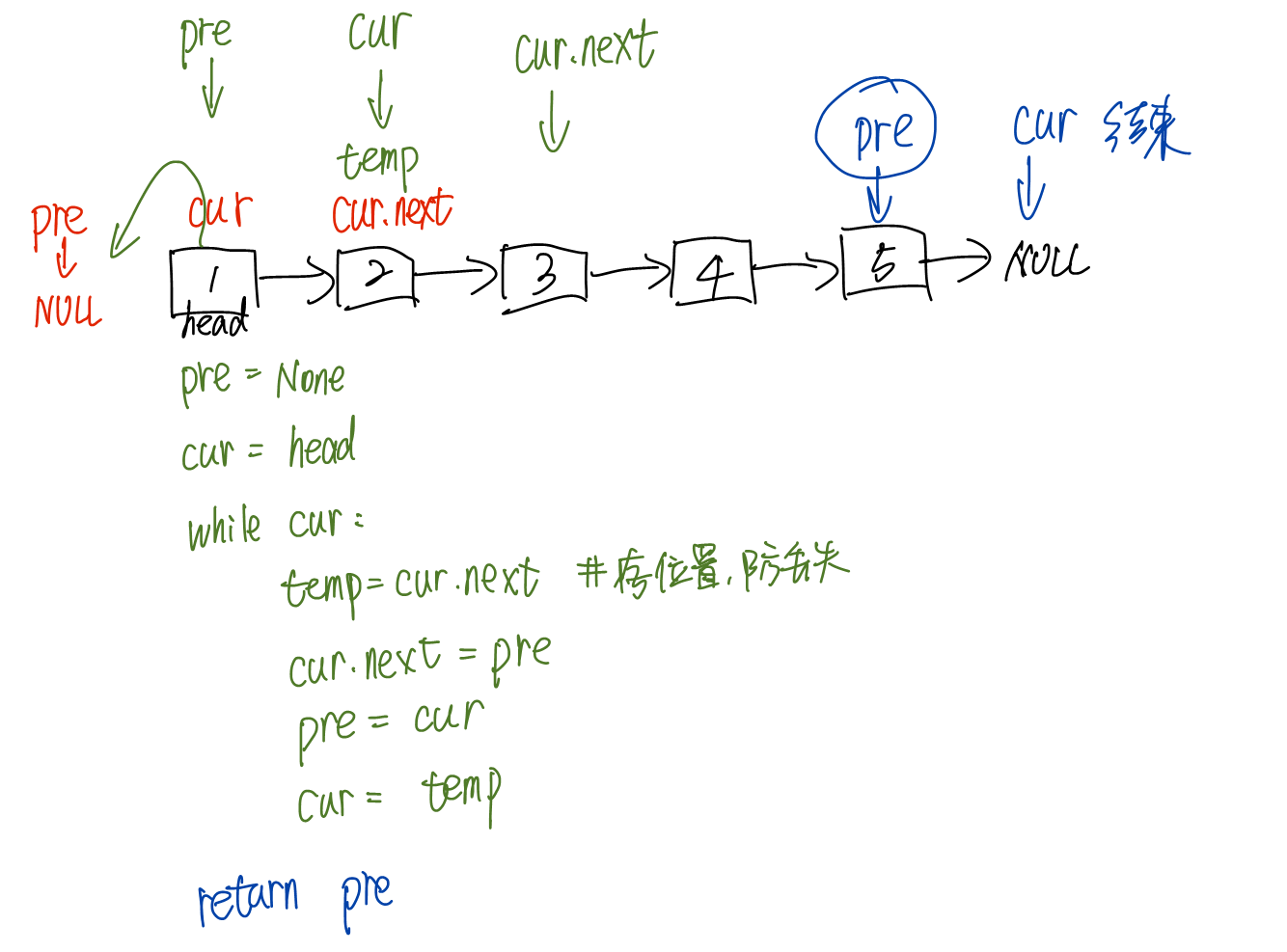
defaddTwoNumbers(l1, l2): deftrans(head): # 反转链表 if head isNoneor head.nextisNone: return head
pre = None cur = head while cur: temp = cur.next cur.next = pre pre = cur cur = temp return pre
l1 = trans(l1) l2 = trans(l2)
ans = 0# 当前轮结果 add_num = 0# 向前进位 mod_num = 0# 余数,需要存进链表里 head = None# 初始空链表
while l1 or l2 or add_num: if l1: a = l1.val l1 = l1.next else: a = 0 if l2: b = l2.val l2 = l2.next else: b = 0 ans = (a + b) + add_num add_num = ans // 10 mod_num = ans % 10 node = ListNode(mod_num) node.next = head head = node return head
# test l1 = ListNode(7) l1.next = ListNode(2) l1.next.next = ListNode(4) l1.next.next.next = ListNode(3) l2 = ListNode(5) l2.next = ListNode(6) l2.next.next = ListNode(4) p = addTwoNumbers(l1, l2) while p: print(p.val) p = p.next
classListNode(): def__init__(self, x): self.val = x self.next = None
defaddTwoNumbers(l1, l2): ans = 0# 当前轮结果 add_num = 0# 进位 mod_num = 0# 余数,也是要保存进链表里的数 head = ListNode(None) p = head # 指针 while l1 or l2 or add_num: if l1: a = l1.val l1 = l1.next else: a = 0 if l2: b = l2.val l2 = l2.next else: b = 0 ans = (a + b) + add_num # 进位也要加 add_num = ans // 10 mod_num = ans % 10 node = ListNode(mod_num) p.next = node p = p.next head = head.next# 去除首部None return head
# test l1 = ListNode(2) l1.next = ListNode(4) l1.next.next = ListNode(3) l2 = ListNode(5) l2.next = ListNode(6) l2.next.next = ListNode(4) p = addTwoNumbers(l1, l2) while p: print(p.val) p = p.next
classListNode: def__init__(self, x): self.val = x self.next = None
defgetKthFromEnd(head, k): slow = fast = head i = 0 while fast: if i >= k: slow = slow.next fast = fast.next i += 1 return slow
# test head = ListNode(1) head.next = ListNode(2) head.next.next = ListNode(3) head.next.next.next = ListNode(4) head.next.next.next.next = ListNode(5) k=2 p = getKthFromEnd(head,k) while p: print(p.val) p = p.next
☆【删除链表的倒数第n个节点】
给定一个链表,删除链表的倒数第 个节点并返回链表的头指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defremoveNthFromEnd(self , head , n ): # write code here #快慢指针找到倒数第n个 fast=head slow=head for i inrange(n):#快指针先走n步 fast=fast.next #特殊情况,要删除的是头节点,则此时fast已经指向尾部的下一个:None ifnot fast: return head.next while fast.next: #使得slow刚好为倒数第n个之前的数字 fast=fast.next slow=slow.next slow.next=slow.next.next#删除倒数第n个 return head
——测试用例
正确的测试用例
空链表,抛异常
n是不是有效的
{1},1,{1,2},2 特殊情况,要删除的是头节点
{1,2},1
【链表中的节点每k个一组翻转】
将给出的链表中的节点每k个一组翻转,返回翻转后的链表 如果链表中的节点数不是k的倍数,将最后剩下的节点保持原样 你不能更改节点中的值,只能更改节点本身。 要求空间复杂度O(1) 用栈,我们把 k 个数压入栈中,然后弹出来的顺序就是翻转的! 这里要注意几个问题: 第一,剩下的链表个数够不够 k 个(因为不够 k 个不用翻转); 第二,已经翻转的部分要与剩下链表连接起来。
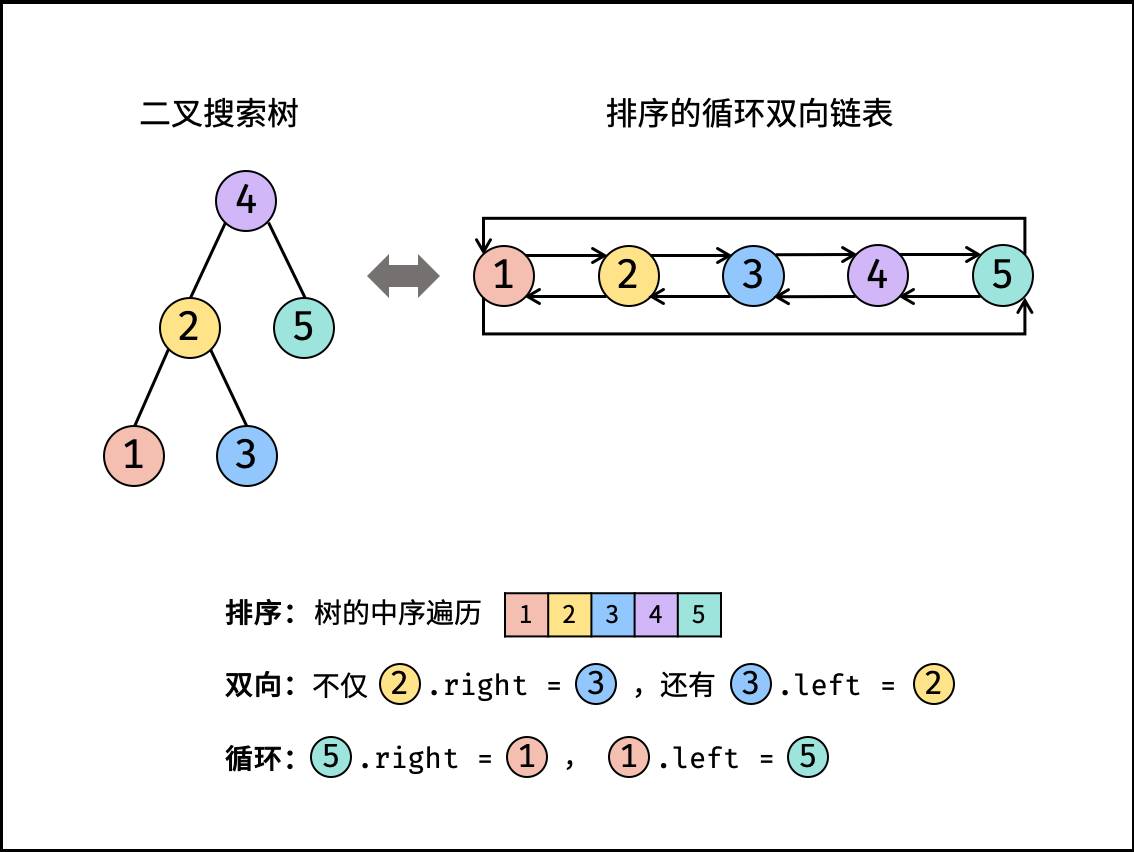
pre = None head = None deftreeToDoublyList(node): defdfs(cur): global pre, head ifnot cur: return dfs(cur.left) # 递归左子树 if pre: # 当pre不为空时:修改双向节点引用,即 pre.right = cur ,cur.left = pre pre.right, cur.left = cur, pre else: head = cur # 当pre为空时:代表正在访问链表头节点,记为 head # 保存cur:更新 pre = cur ,即节点 cur 是后继节点的 pre pre = cur dfs(cur.right)
ifnot root: return dfs(node) # 头尾连接 head.left = pre pre.right = head return head
root = TreeNode(4) root.left = TreeNode(2) root.right = TreeNode(5) root.left.left = TreeNode(1) root.left.right = TreeNode(3) p = treeToDoublyList(root) # print是停不下来的 # print("双向链表正序:") # while p: # print(p.val) # p = p.right print("双向链表倒序:") while p: p = p.left print(p.val)
classSolution: defstrStr(self, haystack: str, needle: str) -> int: if needle notin haystack: return -1 elif needle == '': return0 else: for i inrange(len(haystack)): if haystack[i:len(needle)+i] == needle[:]: return i 详细写法: // 方法一 classSolution: defstrStr(self, haystack: str, needle: str) -> int: a=len(needle) b=len(haystack) if a==0: return0 next=self.getnext(a,needle) p=-1 for j inrange(b): while p>=0and needle[p+1]!=haystack[j]: p=next[p] if needle[p+1]==haystack[j]: p+=1 if p==a-1: return j-a+1 return -1
defgetnext(self,a,needle): next=[''for i inrange(a)] k=-1 next[0]=k for i inrange(1,len(needle)): while (k>-1and needle[k+1]!=needle[i]): k=next[k] if needle[k+1]==needle[i]: k+=1 next[i]=k returnnext
defthreeSum(nums): lens = len(nums) if lens <= 2: return [] nums.sort() # 排序 if nums[0] > 0: return []
res = [] for i inrange(lens): if i > 0and nums[i] == nums[i - 1]: continue l = i + 1 r = lens - 1 target = 0 - nums[i] while l < r: if nums[l] + nums[r] == target: res.append([nums[i], nums[l], nums[r]]) # 还要往继续往中间找 while (l < r and nums[l] == nums[l + 1]): l += 1 while (l < r and nums[r] == nums[r - 1]): r -= 1 l += 1 r -= 1 elif nums[l] + nums[r] < target: l += 1 else: r -= 1 return res
# 第一种:目标是第k大,但由于是升序找partition,所以目标是倒数第K个 deffindKth(nums, k): l = 0 r = len(nums) - 1 target = len(nums) - k
whileTrue: p = partition(nums, l, r) if p == target: return nums[p] elif p < target: l = p + 1 else: # p > target: r = p - 1
defpartition(nums, l, r): pivot = nums[l] while l < r: while l < r and nums[r] >= pivot: r -= 1 nums[l] = nums[r] while l < r and nums[l] <= pivot: l += 1 nums[r] = nums[l] nums[l] = pivot return l
# 第二种:降序找partition,目标是k-1 deffindKth(nums, k): lens = len(nums) l = 0 r = lens - 1 target = k - 1 whileTrue: p = partition(nums, l, r) if p == target: return nums[p] elif p < target: l = p + 1 else: r = p - 1
defpartition(nums, l, r): # 降序排partition pivot = nums[l] while l < r: while l < r and nums[r] <= pivot: # 注意这里 r -= 1 nums[l] = nums[r] # 大的换到左边 while l < r and nums[l] >= pivot: # 注意这里 l += 1 nums[r] = nums[l] # 小的换到右边 nums[l] = pivot return l
# 法二:借助快排partition,找第K,则返回左边序列即可 defsmallestK(arr, k): l = 0 r = len(arr) - 1 target = k - 1 whileTrue: p = partition(arr, l, r) if p == target: return arr[0:k] elif p < target: l = p + 1 else: r = p - 1
defpartition(nums, l, r): pivot = nums[l] while l < r: while l < r and nums[r] >= pivot: r -= 1 nums[l] = nums[r] while l < r and nums[l] <= pivot: l += 1 nums[r] = nums[l] nums[l] = pivot return l
#test s = [4, 5, 1, 6, 2, 7, 3, 8] k = 4 print(smallestK(s, k)
# 法三:借助大顶堆,仅维护K个长度的堆,遍历数组,当新元素小于堆顶元素时,更新堆顶元素,调整堆 defHeadAdjust(arr, i, n): # 以i为根节点进行堆调整 largest = i l = 2 * i + 1 r = 2 * i + 2 if l < n and arr[l] > arr[largest]: largest = l if r < n and arr[r] > arr[largest]: largest = r if largest != i: arr[i], arr[largest] = arr[largest], arr[i] HeadAdjust(arr, largest, n)
defsmallestK(arr, k): if k == 0: return [] # 构建一个只有k个数的大顶堆 hp = arr[:k] for i inrange((k) // 2 - 1, -1, -1): # 从有子节点的节点开始判断就行 HeadAdjust(hp, i, k) # 遍历数组,当新元素小于堆顶元素时,更新堆顶元素,调整堆 for num in arr[k:]: if num < hp[0]: hp[0] = num HeadAdjust(hp, 0, k) return hp
# test s = [4, 5, 1, 6, 2, 7, 3, 8] k = 0 print(smallestK(s, k))
# 先判空 # 令最长公共前缀 ans 的值为第一个字符串,进行初始化 # 遍历后面的字符串,依次与ans比较,找出公共前缀 # 如果不为空则返回,为空则return "" deflongestCommonPrefix(strs): ifnot strs: return"" ans = strs[0] for s in strs[1:]: iflen(s) < len(ans): ans = ans[:len(s)] # 会有字符串比初始小的情况 for i inrange(len(s)): if i < len(ans) and s[i] != ans[i]: # 注意这里i可能会超出ans索引 ans = ans[:i] # 和公共前缀字符不匹配,截断ans return ans
classWordFilter(object): def__init__(self, words): """ :type words: List[str] """ self.a={} for ind,i inenumerate(words): for j inrange(len(i)+1): for k inrange(len(i)+1): now=i[:j]+'$'+i[k:] self.a[now]=ind






 微信
微信 支付宝
支付宝



