
面试QA整理(6)——java
Welcome to xpt’s blog! 2021年准备秋招期间整理的一些笔记,分享给大家!
文档分享的初衷是给师弟师妹们作为参考,主要是适合想去大厂+测试开发岗的朋友们。
建议大家自己整理文档,把我的文档作为参考,有些东西自己整理,自己去写出来,才是最适合你自己的!
文章还未精细整理,如存在错误之处,可以邮件or微信反馈给我呀,感激不尽!
想进大厂,要抓住提前批免笔试的机会!(例如京东、字节、百度等报名时间一般为七月,面试时间为报名后的一周内,面试一般为3轮,面试相关经验后续我会单独再写blog分享^_^,也欢迎大家来跟我talk,一定知无不言。)
本人情况:普通211、研究生、有京东、百度、以及字节提前批测开岗offer。7月初开始准备,准备太迟,一边准备一边投简历+面试。
- 投递简历时间:京东(7.14),字节(7.30),百度(7.30)
- 三轮面试时间:京东(7.21-7.22-7.26),字节(8.4-8.6-8.9),百度(8.9-8.12-8.16)
- 意向书时间:京东(8.12),字节(8.16),百度(9.9)
京东提前批开始很早,我投的时候已经是第二批。经过京东几轮面试,熟悉了面试流程,大概掌握了测开岗会问些什么问题。
字节和百度提前批我是在ddl前一天投递,其实已经算很迟了,hc不多了。
投递要趁早,很多岗位有固定hc。
多拿offer,才有谈薪资的底气。
我面试的岗位有以下:
1、测试开发岗(京东、百度、以及字节提前批)
2、银行java开发岗(所以我会整理一点java,银行问的都很简单,所以我这里对java的整理比较少)
整理的内容均来源于历年网络上分享的面经(主要来源于牛客),以及我面试时被问过的问题,list如下:
(1)——计算机网络
(2)——操作系统
(3)——数据库
(4)——数据结构
(5)——python
(6)——java
(7)——linux
(8)——常考编程题
(9)——测试开发相关知识
面试QA整理(6)——java
面试官会问你熟悉的语言,我一般都说python,有些面试还会问些java,这里整理的比较少。
面向对象的三大特征:封装性、继承性、多态性。
封装性在Java当中的体现:
- 1.方法就是一种封装
- 2.关键字private也是一 种封装
封装就是将一 些细节信息隐藏起来,对于外界不可见。
继承是多态的前提,如果没有继承,就没有多态。
继承主要解决的问题就是:共性抽取。
多态
一个对象拥有多种形态,这就是:对象的多态性。
多态: 是指同一行为,具有多个不同表现形式
小明是一个对象,
这个对象既有学生形态,也有人类形态。
一个对象拥有多种形态,这就是:
对象的多态性。
对象的内存分配方式
Java堆这块内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都要在堆上分配。
创建对象内存分配
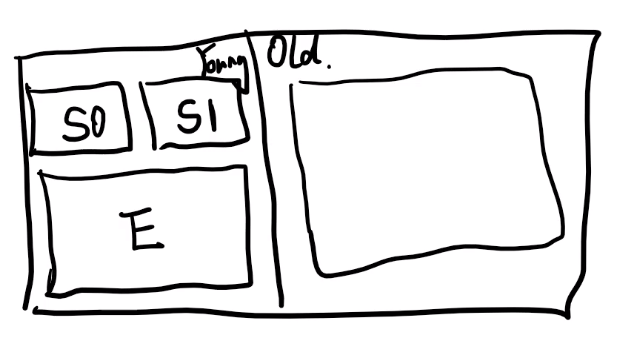
Ⅰ、将内存进行了划分,一部分是年轻代(Young区),还有一部分是老年代(Old区)
Ⅱ、年轻代也进行了划分,分别是1个Eden区和2个Survivor区;Old区就是整个的一块
Ⅲ、new的对象产生在Eden区,当Eden区快满的时候,就会触发GC,这个GC是在Young区的,所以也叫Young GC,Young GC采用的是复制算法,把在Eden区需要删除的打上一个标记,不需要删除的复制到Survivor区(S0或者S1均可,内存大小 S0:S1:E区=1:1:8)。
为什么要2块Survivor区?因为这两个S区是交替工作的,在E区打完标记后,不需要删除的被放到S0区,然后把E区+S1区一起删除,等下一次E区快满的时候,将不需要删除的被放到S1区,然后把E区+S0区一起删除…如此往复的工作,比将内存一分为二的效率要高一些的(主要是针对 对象的朝生夕死的特点去设计的)
Ⅳ、Old区:在每一次的Young GC的时候,存活下来的对象的年龄都会加1,直到年龄到达了?岁,它就不在Survivor区里面进行复制了,而是直接将不需要删除的对象放到Old区里面,因为之前的Young GC都没去掉,说明可能要过很久才能去掉;
除了存了年龄大于等于?岁的,还存了大的对象(如:1个1千万大小的int数组),Old区满的时候也会触发GC,Old GC一般也会伴随着Young GC,所以也叫做Full GC,Full GC会引起Stop-The-World,整个Java程序直接暂停,来全力的进行垃圾回收,
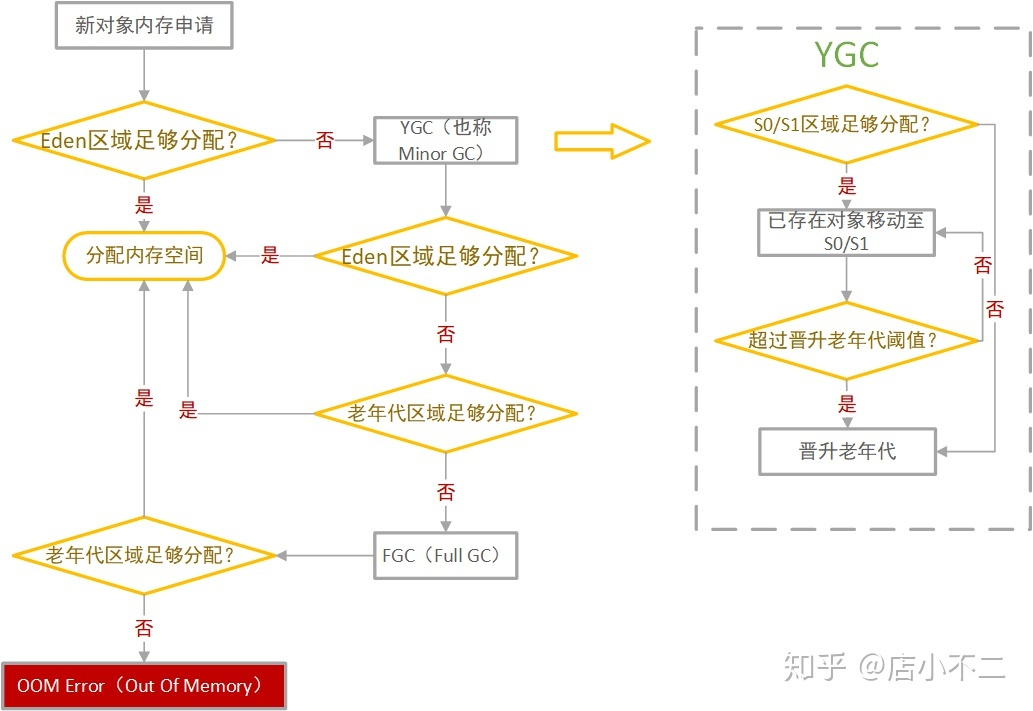
堆与栈区别

堆与栈实际上是操作系统对进程占用的内存空间的两种管理方式,主要有如下几种区别:
(1)管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
(2)空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。理论上,程序员可申请的堆大小为虚拟内存的大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
(3)生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(4)分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由操作系统进行释放,无需我们手工实现。
(5)分配效率不同。栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
(6)存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。当主函数调用另外一个函数的时候,要对当前函数执行断点进行保存,需要使用栈来实现,首先入栈的是主函数下一条语句的地址,即扩展指针寄存器的内容(EIP),然后是当前栈帧的底部地址,即扩展基址指针寄存器内容(EBP),再然后是被调函数的实参等,一般情况下是按照从右向左的顺序入栈,之后是被调函数的局部变量,注意静态变量是存放在数据段或者BSS段,是不入栈的。出栈的顺序正好相反,最终栈顶指向主函数下一条语句的地址,主程序又从该地址开始执行。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
从以上可以看到,堆和栈相比,由于大量malloc()/free()或new/delete的使用,容易造成大量的内存碎片,并且可能引发用户态和核心态的切换,效率较低。栈相比于堆,在程序中应用较为广泛,最常见的是函数的调用过程由栈来实现,函数返回地址、EBP、实参和局部变量都采用栈的方式存放。虽然栈有众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,主要还是用堆。
无论是堆还是栈,在内存使用时都要防止非法越界,越界导致的非法内存访问可能会摧毁程序的堆、栈数据,轻则导致程序运行处于不确定状态,获取不到预期结果,重则导致程序异常崩溃,这些都是我们编程时与内存打交道时应该注意的问题。
线程相关
线程池
线程池:其实就是一个容纳多个线程的容器,其中的线程可以反复使用,【执行完一个任务,并不被销毁,而是可以继续执行其他的任务】。省去了频繁创建线程对象的操作,无需反复创建线程而消耗过多资源。
合理利用线程池能够带来三个好处:
- 降低资源消耗。减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。使用线程池可以进行统一分配、调优和监控。可以根据系统的承受能力,调整线程池中工作线程的数目,防止因为消耗过多的内存,而把服务器累趴下
- (每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
创建线程的方式
有三种方式可以用来创建线程:
继承Thread类
实现Runnable接口
应用程序可以使用Executor框架来创建线程池
实现Runnable接口这种方式更受欢迎,因为这不需要继承Thread类。在应用设计中已经继承了别的对象的情况下,这需要多继承(而Java不支持多继承),只能实现接口。同时,线程池也是非常高效的,很容易实现和使用。
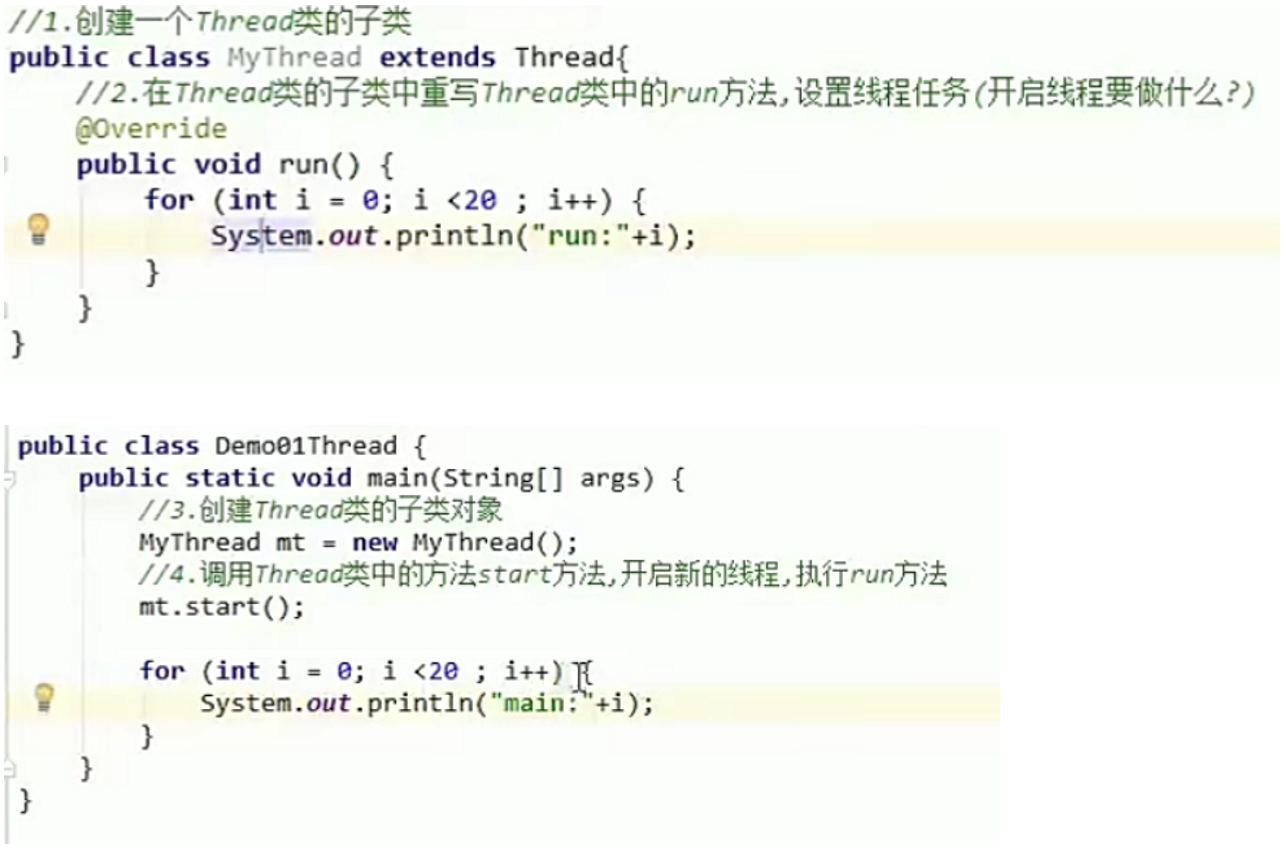
方式一、创建Thread类的子类
实现步骤:
- 1.创建一个Thread类的子类
- 2.在Thread类的子类中重写Thread类中的run方法,设置线程任务(开启线程要做什么?)
- 3.创建Thread类的子类对象
- 4.调用Thread类中的方法start方法
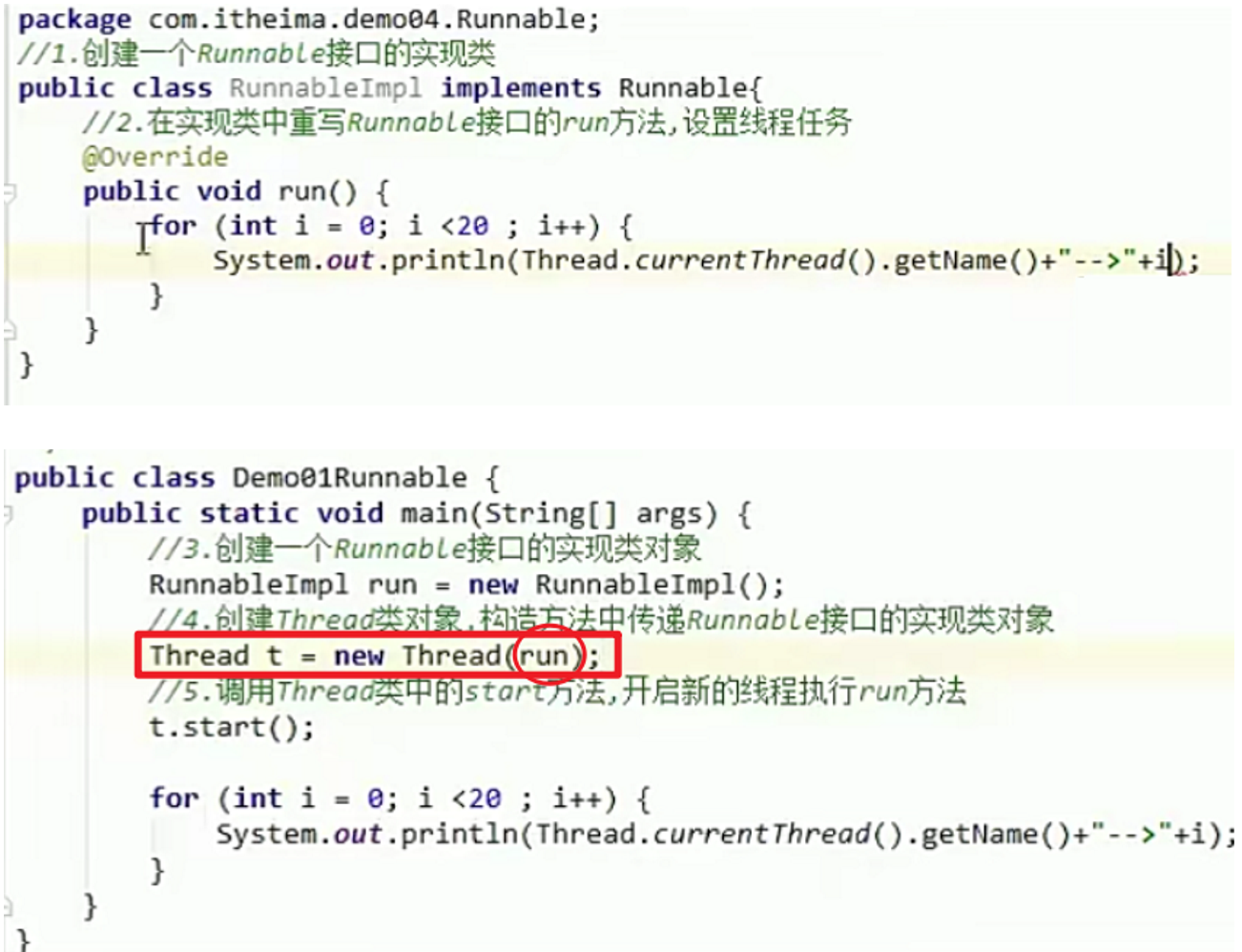
方式二、实现Runnable接口
实现步骤:
1.创建一个Runnable接口的实现类
2.在实现类中重写Runnable接口的run方法,设置线程任务
3.创建一个Runnable接口的实现类对象
4**.创建Thread类对象**,构造方法中传递Runnable接口的实现类对象
5.调用Thread类中的start方法,开启新的线程执行run方法
抽象类与接口的区别
接口和抽象类都是继承树的上层,他们的共同点如下:
都是上层的抽象层。
都不能被实例化
都能包含抽象的方法,这些抽象的方法用于描述类具备的功能,但是不比提供具体的实现。
他们的区别如下:在抽象类中可以写非抽象的方法,从而避免在子类中重复书写他们,这样可以提高代码的复用性,这是抽象类的优势;接口中只能有抽象的方法。
一个类只能继承一个直接父类,这个父类可以是具体的类也可是抽象类;但是一个类可以实现多个接口。
类和对象的区别
类是描述,对象是实例。
类与对象的关系
●类是对一类事物的描述,是抽象的。
●对象是一类事物的实例,是具体的。
●类是对象的模板,对象是类的实体。
类:是一组相关属性和行为的集合。可以看成是一类事物的模板,使用事物的属性特征和行为特征来描述该类事物。
对象:是一类事物的具体体现。对象是类的一个实例,必然具备该类事物的属性和行为。
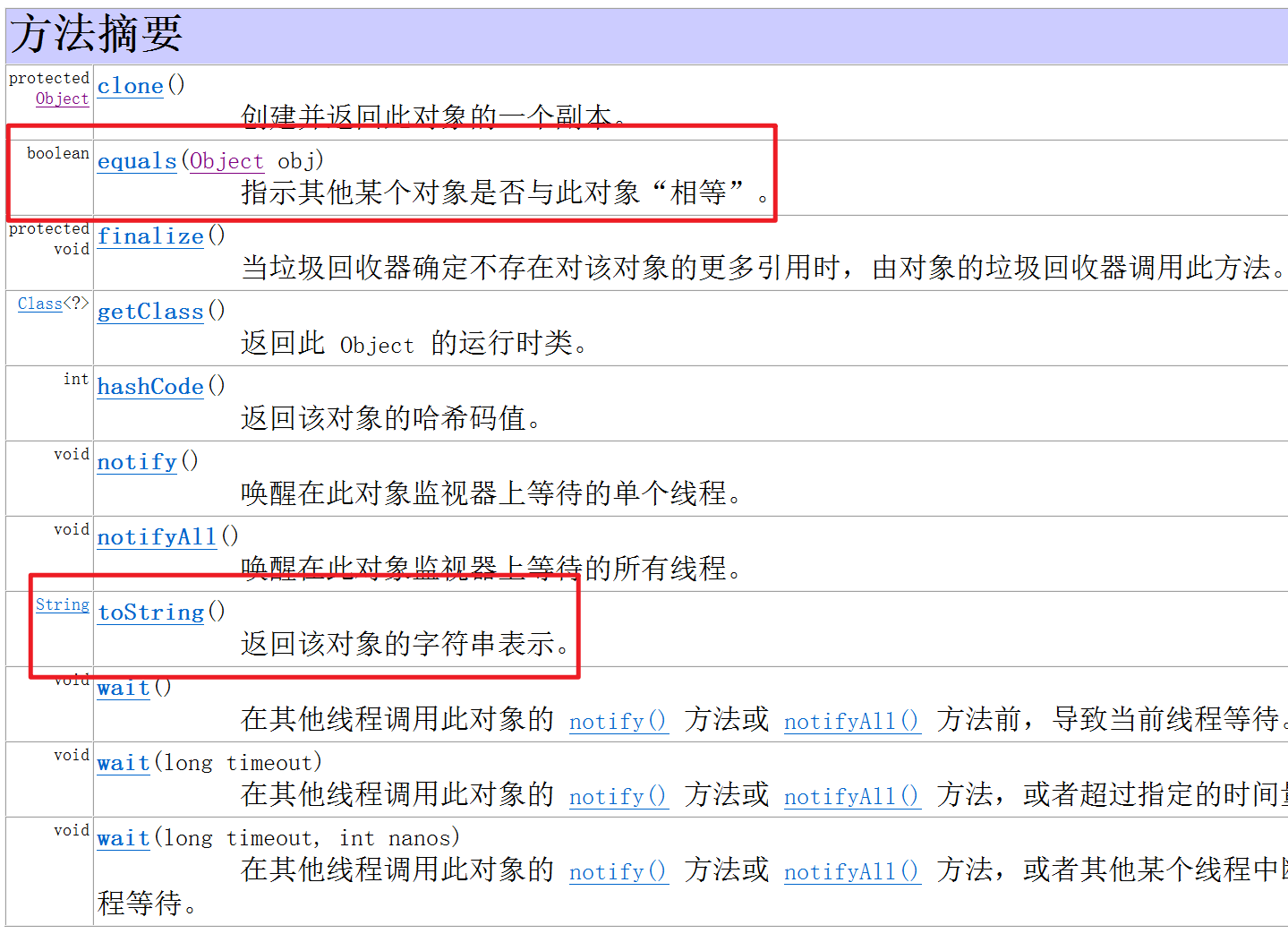
object类中有哪些方法
boolean equals(Object obj) 指示其他某个对象是否与此对象“相等”
public String toString(): 返回该对象的字符串表示。
void wait()
在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待。
void notify()
唤醒在此对象监视器上等待的单个线程。
会继续执行wait方法之后的代码
Object类中wait带参方法
使用wait(long m)方法,wait方法如果在毫秒值结束之后,还没有被notify唤醒,就会自动醒来,线程睡醒进入到Runnable/Blocked状态
唤醒的方法:
void notify() 唤醒在此对象监视器上等待的单个线程。
void notifyAll() 唤醒在此对象监视器上等待的所有线程。
Java 容器都有哪些?
Java 容器分为 Collection 和 Map 两大类,其下又有很多子类,如下所示:
Collection
List
ArrayList
LinkedList
Vector
Set
HashSet
LinkedHashSet
TreeSet
Map
HashMap
LinkedHashMap
TreeMap
ConcurrentHashMap
Hashtable
数据容器主要分为了两类:
Collection: 存放独立元素的序列。
Map:存放key-value型的元素对。(这对于需要利用key查找value的程序十分的重要!)
Map相关
HashMap的get方法能否判断某个元素是否在map中?
HashMap 基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。
public V get(Object key) 根据指定的键,在Map集合中获取对应的值。
• 返回值:V
○ key存在,返回对应的value值
○ key不存在,返回null
boolean containsKey(Object key) 判断集合中是否包含指定的键。
• 包含返回true,不包含返回false
list 相关
arraylist和linkedlist区别
ArrayList集合
java.util.ArrayList 集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为
查询数据、遍历数据,所以 ArrayList 是最常用的集合。
LinkedList集合
java.util.LinkedList 集合数据存储的结构是链表结构。元素增删快,查找慢。
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法
数组(Array)和列表(ArrayList)的区别
Array和ArrayList的不同点:
Array可以包含基本类型和对象类型,ArrayList只能包含对象类型。
Array大小是固定的,ArrayList的大小是动态变化的。
ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
final关键字的作用
Java提供了final 关键字,用于修饰不可改变内容。
final:不可改变。可以用于修饰类、方法和变量。
- 类:被修饰的类,不能被继承。
- 方法:被修饰的方法,不能被重写。
- 变量:被修饰的变量,不能被重新赋值。
static关键字的作用
关于static 关键字的使用,它可以用来修饰的成员变量和成员方法,
被修饰的成员是属于类的,而不是单单是属于某个对象的。
也就是说,既然属于类,就可以不靠创建对象来调用了。
凡是本类的对象,都共享同一份。
static关键字最基本的用法是:
1、被static修饰的变量属于类变量,可以通过类名.变量名直接引用,而不需要new出一个类来
2、被static修饰的方法属于类方法,可以通过类名.方法名直接引用,而不需要new出一个类来
被static修饰的变量、被static修饰的方法统一属于类的静态资源,是类实例之间共享的,换言之,一处变、处处变。JDK把不同的静态资源放在了不同的类中而不把所有静态资源放在一个类里面,很多人可能想当然认为当然要这么做,但是是否想过为什么要这么做呢?个人认为主要有三个好处:
1、不同的类有自己的静态资源,这可以实现静态资源分类。比如和数学相关的静态资源放在java.lang.Math中,和日历相关的静态资源放在java.util.Calendar中,这样就很清晰了
2、避免重名。不同的类之间有重名的静态变量名、静态方法名也是很正常的,如果所有的都放在一起不可避免的一个问题就是名字重复,这时候怎么办?分类放置就好了。
3、避免静态资源类无限膨胀,这很好理解。
简述一下servlet的生命周期
Servlet的生命周期可以分为初始化阶段,运行阶段和销毁阶段三个阶段
servlet的生命周期就是从servlet出现到销毁的全过程。主要分为以下几个阶段:
加载类- ->实例化(为对象分配空间)- -> 初始化(为对象的属性赋值)一> 请求处理(服务阶段)- > 销毁
(1)加载和实例化
当Servlet容器启动或客户端发送一个请求时,Servlet容器会查找内存中是否存在该Servlet实例,若存在,则直接读取该实例响应请求;如果不存在,就创建一个Servlet实例。
(2) 初始化
实例化后,Servlet容器将调用Servlet的init()方法进行初始化(一些准备工作或资源预加载工作)。
(3)服务
初始化后,Servlet处于能响应请求的就绪状态。当接收到客户端请求时,调用service()的方法处理客户端请求,HttpServlet的service()方法会根据不同的请求 转调不同的doXxx()方法。
(4)销毁
当Servlet容器关闭时,Servlet实例也随时销毁。其间,Servlet容器会调用Servlet 的destroy()方法去判断该Servlet是否应当被释放(或回收资源)。
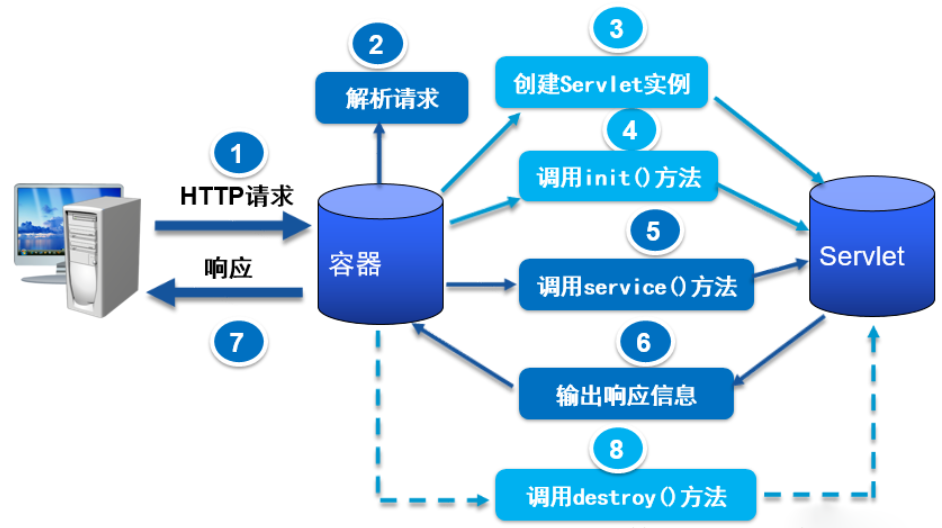

servlet是干什么的
浏览器发送一个HTTP请求,HTTP请求由Web容器分配给特定的Servlet进行处理,Servlet的本质是一个Java对象,这个对象拥有一系列的方法来处理HTTP请求。常见的方法有doGet(),doPost()等。Web容器中包含了多个Servlet,特定的HTTP请求该由哪一个Servlet来处理是由Web容器中的web.xml来决定的。

 微信
微信 支付宝
支付宝




