
面试QA整理(7)——linux
Welcome to xpt’s blog! 2021年准备秋招期间整理的一些笔记,分享给大家!
文档分享的初衷是给师弟师妹们作为参考,主要是适合想去大厂+测试开发岗的朋友们。
建议大家自己整理文档,把我的文档作为参考,有些东西自己整理,自己去写出来,才是最适合你自己的!
文章还未精细整理,如存在错误之处,可以邮件or微信反馈给我呀,感激不尽!
想进大厂,要抓住提前批免笔试的机会!(例如京东、字节、百度等报名时间一般为七月,面试时间为报名后的一周内,面试一般为3轮,面试相关经验后续我会单独再写blog分享^_^,也欢迎大家来跟我talk,一定知无不言。)
本人情况:普通211、研究生、有京东、百度、以及字节提前批测开岗offer。7月初开始准备,准备太迟,一边准备一边投简历+面试。
- 投递简历时间:京东(7.14),字节(7.30),百度(7.30)
- 三轮面试时间:京东(7.21-7.22-7.26),字节(8.4-8.6-8.9),百度(8.9-8.12-8.16)
- 意向书时间:京东(8.12),字节(8.16),百度(9.9)
京东提前批开始很早,我投的时候已经是第二批。经过京东几轮面试,熟悉了面试流程,大概掌握了测开岗会问些什么问题。
字节和百度提前批我是在ddl前一天投递,其实已经算很迟了,hc不多了。
投递要趁早,很多岗位有固定hc。
多拿offer,才有谈薪资的底气。
我面试的岗位有以下:
1、测试开发岗(京东、百度、以及字节提前批)
2、银行java开发岗(所以我会整理一点java,银行问的都很简单,所以我这里对java的整理比较少)
整理的内容均来源于历年网络上分享的面经(主要来源于牛客),以及我面试时被问过的问题,list如下:
(1)——计算机网络
(2)——操作系统
(3)——数据库
(4)——数据结构
(5)——python
(6)——java
(7)——linux
(8)——常考编程题
(9)——测试开发相关知识
面试QA整理(7)——linux
常用linux命令

1、环境部署
①远程连接服务器操作(客户端连接服务器)
Xshell、VScode
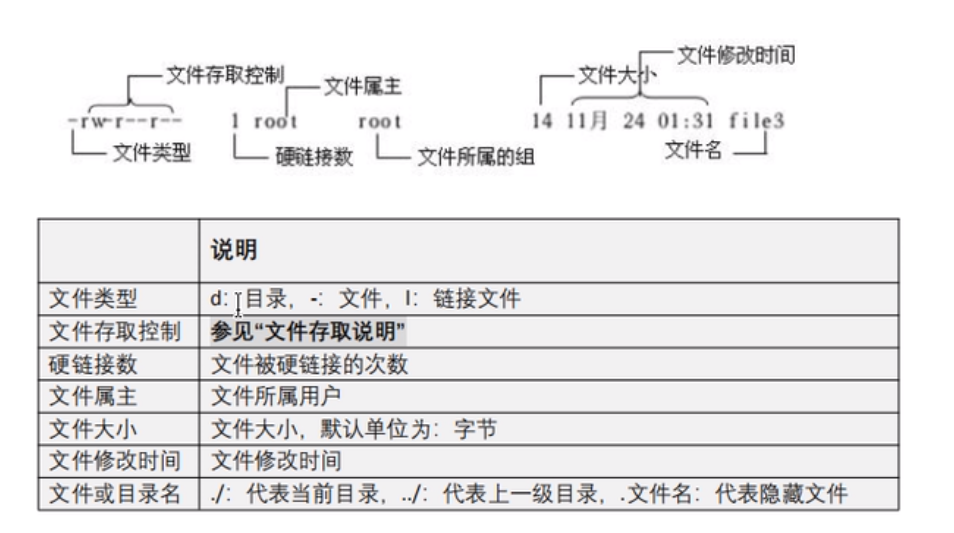
②常用命令(查看目录内容Is命令、当前工作目录pwd、切换工作目录cd、创建目录mkdir、
③文件操作(创建文件touch 、复制cp、移动mv重命名、删除rm )
④压缩操作(解压)
文件压缩解压: zip、 unzip
压缩解压: gzip .gz后缀,解压-d
打包 tar -cvf
解包 tar -xvf
查看包 tar -tvf
tar只负责打包文件, 但不压缩,
在tar命令中增加一个选项**(-z)**可以调用gzip实现了一个压缩的功能, 实行一个先打包后压缩的过程
用gzip压缩tar打包后的文件, 其扩展名一般用xxxx.tar.gz
解压到指定目录: -C (大写字母“C”)
⑤权限操作(切换账户、文件授权)
切换用户:su
exit退出当前登录用户
useradd添加用户
userdel删除用户
设置修改用户密码: passwd 用户名
whoami
修改文件权限: chmod
字母法: chmod u/g/o/a +/-/= rwx 文件
⑥系统命令操作(进程相关、重启、关机)
df查看磁盘空间
ps显示系统进程,-aux查看所有进程详细信息(静态的看)ps -aux
top动态查看进程信息(动态的看)
kill -9 pid 彻底终止进程
关机重启: reboot、 shutdown
⑦网络相关命令
ping测试目标主机是否网络连通
ifconfig查看网卡信息
2、日志查看
①文件查看(全部查看、从头查看、从尾查看、过滤)
cat一次显示所有
分屏显示: more
查看或者合并文件内容: cat
cat test1.txt test2.txt
文本搜索: grep
grep ‘a’ 1.txt
grep搜索内容串可以是正则表达式
正则表达式是对字符串操作的一种逻辑公式, 就是用事先定义好的一些特定字符、 及这些特定字符的组合, 组成一个“规则字符串”, 这个“规则字符串”用来表达对字符串的一种过滤逻辑。
②文件编辑(编辑器命令)
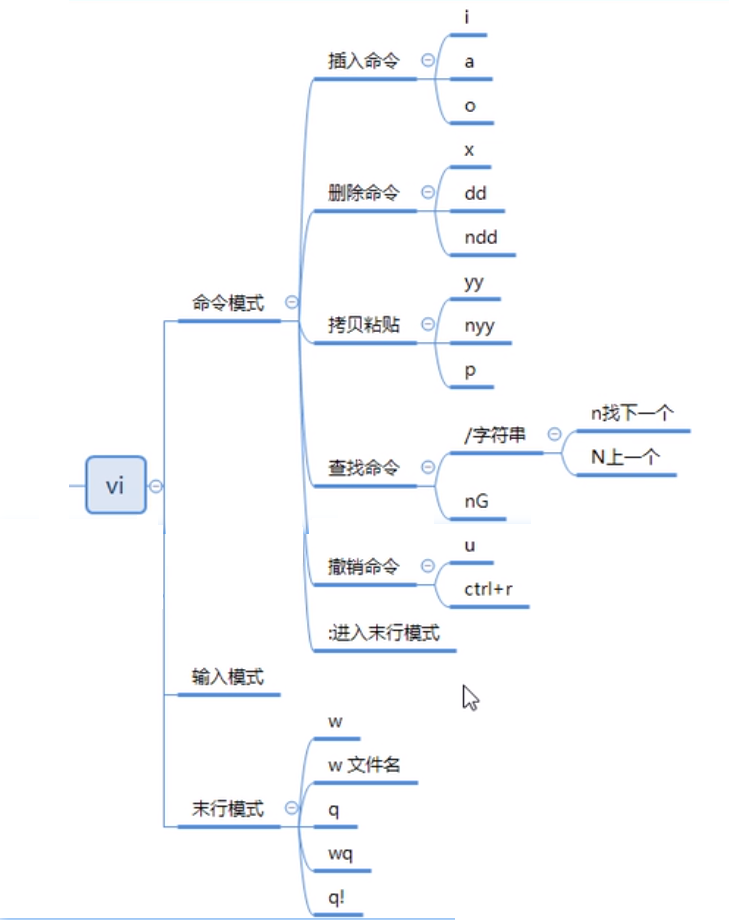
Vi有三种基本工作模式:
- 命令模式
- 文本输入模式
- 末行模式
进入插入模式 :
i: 插入光标前一个字符
I: 插入行首
a: 插入光标后一个字符
A: 插入行未
o: 向下新开一行,插入行首
O: 向上新开一行,插入行首
ESC:从插入模式或末行模式进入命令模式
输出重定向命令: >
ls > test.txt ( test.txt 如果不存在, 则创建, 存在则覆盖其内容 )
注意: >输出重定向会覆盖原来的内容, >>输出重定向则会追加到文件的尾部。
**建立链接文件: ln **
查找文件: find
查看命令位置: which



查看Linux端口占用(lsof -i: 端口号/netstat -tunlp|grep 端口号)
1 | lsof -i: 端口号 |
kill -15 和 kill -9 的区别
kill -9 PID 是操作系统从内核级别强制杀死一个进程. killed
kill -15 PID 可以理解为操作系统发送一个通知告诉应用主动关闭. terminated
SIGTERM(15) 的效果是正常退出进程,退出前可以被阻塞或回调处理。并且它是Linux缺省的程序中断信号。
当使用kill -15时,系统会发送一个SIGTERM的信号给对应的程序。当程序接收到该信号后,具体要如何处理是自己可以决定的。
这时候,应用程序可以选择:
- 1、立即停止程序
- 2、释放响应资源后停止程序
- 3、忽略该信号,继续执行程序
因为kill -15信号只是通知对应的进程要进行”安全、干净的退出”,程序接到信号之后,退出前一般会进行一些”准备工作”,如资源释放、临时文件清理等等,如果准备工作做完了,再进行程序的终止。但是,如果在”准备工作”进行过程中,遇到阻塞或者其他问题导致无法成功,那么应用程序可以选择忽略该终止信号。这也就是为什么我们有的时候使用kill命令是没办法”杀死”应用的原因,因为默认的kill信号是SIGTERM(15),而SIGTERM(15)的信号是可以被阻塞和忽略的。和kill -15相比,kill -9就相对强硬一点,系统会发出SIGKILL信号,他要求接收到该信号的程序应该立即结束运行,不能被阻塞或者忽略。所以,相比于kill -15命令,kill -9在执行时,应用程序是没有时间进行”准备工作”的,所以这通常会带来一些副作用,数据丢失或者终端无法恢复到正常状态等。
Linux前台进程和后台进程区别
前台进程:是在终端中运行的命令,那么该终端就为进程的控制终端,一旦这个终端关闭,这个进程也随之消失。
后台进程:也叫守护进程(Daemon),是运行在后台的一种特殊进程,不受终端控制,它不需要终端的交互;Linux的大多数服务器就是使用守护进程实现的。比如Web服务器的httpd等。
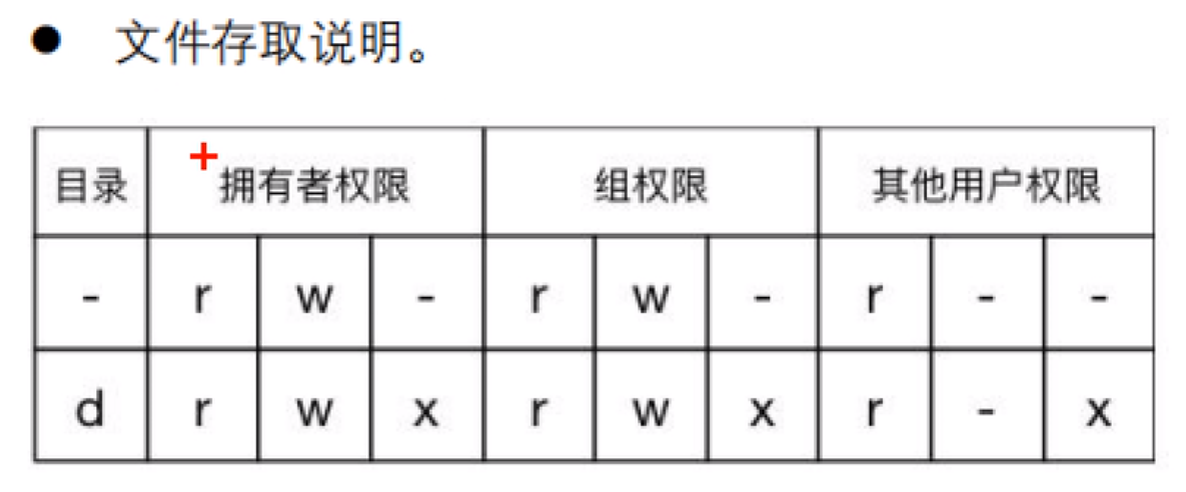
修改文件权限chmod
字母法: chmod u/g/o/a +/-/= rwx 文件
读,写,执行。对应字母为 r、w、x
1 | [ugoa...] |
规定数字 4 、2 和 1表示读、写、执行权限,即r=4,w=2,x=1
1 | 如: |
每个文件都可以针对三个粒度,设置不同的rwx(读写执行)权限。即我们可以用用三个8进制数字分别表示 拥有者 、群组 、其它组( u、 g 、o)的权限详情,并用chmod直接加三个8进制数字的方式直接改变文件权限
递归地创建目录 mkdir -p a/b/c
当你要创建的目录包含子目录时,你需要使用 -p 参数。如果 mkdir 找不到父目录,那么这个参数会首先帮助创建父目录。
1 | mkdir -p a/b/c |
查看CPU的使用效率 top
awk命令
AWK, 数据过滤工具 (类似于grep,比grep强大),属数据处理引擎,基于模式匹配检查输入文本,逐行处理并输出。通常用在Shell脚本中,获取指定的数据,单独使用时,可对文本数据做统计。
1 | awk是行处理器 |
1 | #[ :]+这个是正则表达式,+表示一个或多个,这里就表示一个或多个空格或冒号 |
1 | awk [选项] 'BEGIN{编辑指令}{编辑指令}END{编辑指令}' 文件 |
【例一】只查看test.txt文件(100行)内第20到第30行的内容(企业面试)
1 | awk '{if(NR>=20 && NR<=30) print $0}' test.txt |
【例二】已知test.txt文件内容为:I am Poe,, my qq is 33794712 (Poe后面是逗号逗号空格)
请从该文件中过滤出’Poe’字符串与33794712,最后输出的结果为:Poe 33794712
1 | awk -F '[ ,]+' '{print $3" "$7}' test.txt |
【例三】已知test.txt文件,内容用\t分隔,请输出第二列
1 | aaa bbb ccc |
【例四】linux中一test.txt文件,共有4列,每列之间用tab隔开。现想把第二列复制一次,插入到第二列后。生成5列用tab分割的数据
1 | 1 132 T G |
【例五】计算在200以内,能同时被3和13整除的整数个数。
1 | seq 200 |awk 'BEGIN{i=0} ($0%3==0)&&($0%13==0) {i++}END{print i}' |
【例六】输出偶数行文本
1 | test.txt |
linux中awk下 gsub、sub函数用法
gsub函数则使得在所有正则表达式被匹配的时候都发生替换
gsub匹配所有的符合模式的字符串
gsub(regular expression, subsitution string, target string);简称 gsub(r,s,t)
sub和gsub的区别:
sub匹配第一次出现的符合模式的字符串。
gsub匹配所有的符合模式的字符串
gsub返回的是替换的次数
1 | test.txt内容: |
tail
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
- -f 循环读取
- -n<行数> 显示文件的尾部 n 行内容
tail -n +5 1.log显示文件1.log从第 5行至文件末尾 的内容tail -n -5 1.logortail -n 5 1.log显示的结果相同,均是文件末尾最后 5 行内容。
管道符
对linux命令的输出结果进行再次处理,就可以使用管道符+管道命令
ps命令可以查看系统中的进程,但如果需要查看指定进程,就需要在ps命令返回的结果中进行筛选,如查看java进程:ps -aux |grep java
正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。


scp命令
在linux 下scp 命令主要用来在不同主机之间做数据的安全拷贝的。
scp 命令可以将文件从本地的计算机中拷贝到远程的主机中,或者从远程计算机中拷贝文件到本地主机,
scp命令使用的安全加密的协议,所以在远程拷贝数据的时候会比较安全,不会被黑客截取。
linux实例
一个文件夹下有多个文件夹,如何删除该目录下的所有txt文件?
1 | find ./ -name "*.txt" | xargs rm -rf |
查找当前目录以及子目录下以.c结尾的,且包含”hello”的文件—— find grep xargs
1 | find ./ -name "*.c"| xargs grep "hello" -on |

可以看到结果中显示了符合要求的文件,及该文件包含hello的行数
find命令
-type f 表示文件要寻找的是文件
-name “*.txt” 表示文件名为 .txt结尾的 所有文件。 *表示所有
参数代换命令:xargs。xargs表示展开find获得的结果,使其作为grep的参数
grep的-o参数只显示匹配的内容,-n参数是显示匹配的行数(如果不写o,会把匹配的那一行所有都显示出来
linux查找目录下包含字符串aaa的文件
1 | grep -rn "aaa" ./ |
统计一个文件中某个/多个字符串出现次数——grep或awk
1 | 单个字符串可以不加引号 |
grep -o 一条数据里面有多个相同,会统计相同的次数grep 一条数据里面有多个相同,会统计一次次数
对linux命令的输出结果进行再次处理,就可以使用管道符
wc 命令使用 -l 命令选项来打印文件中的新行数
1 | test.txt 文件内容: |
一段linux上统计平均响应时间的awk脚本
1 | grep '15:10:00' daily-2015-12-20.log| grep 'RESPONSE'|awk 'BEGIN {t = 0;} {split($10,a,"=");t+=a[2];} END {print t/NR;}' |
shell脚本
test.sh中第一行一定是 “#! /bin/bash” 它代表的意思是,该文件使用的是bash语法。如果不设置该行,那么你的shell脚本就不能被执行。
Shell脚本的执行很简单,直接”sh test.sh“ 即可,另外你还可以这样执行:chmod +x test.sh ./test.sh
默认我们用vim编辑的文档是不带有执行权限的,所以需要加一个执行权限,那样就可以直接使用’./filename’ 执行这个脚本了。
另外使用sh命令去执行一个shell脚本的时候是可以加-x选项,”sh -x test.sh“来查看这个脚本执行过程的
定义变量的格式为 “变量名=变量的值”。当在脚本中引用变量时需要加上’$’符号
数学计算要用’[ ]’括起来并且外头要带一个’$’
read命令,它可以从标准输入获得变量的值,后跟变量名。”read x”表示x变量的值需要用户通过键盘输入得到
read -p 选项类似echo的作用。
shell脚本的预设变量。shell脚本在执行的时候后边是可以跟变量的,而且还可以跟多个。
$1和$2,这其实就是shell脚本的预设变量,其中$1和$2的值就是在执行的时候输入的。另外还有一个$0,不过它代表的是脚本本身的名字。
写一个shell脚本,在一个文件夹中有多个日志,每个日志里面记录了一些访问信息,统计该文件夹下所有日志文件中,带有toutiao的字段出现了多少次
1 |
|
linux的用户态和内核态有什么区别
通过系统调用将Linux整个体系分为用户态和内核态(或者说内核空间和用户空间)。
那内核态到底是什么呢?其实从本质上说就是我们所说的内核,它是一种特殊的软件程序,特殊在哪儿呢?控制计算机的硬件资源,例如协调CPU资源,分配内存资源,并且提供稳定的环境供应用程序运行。
用户态就是提供应用程序运行的空间,为了使应用程序访问到内核管理的资源例如CPU,内存,I/O。内核必须提供一组通用的访问接口,这些接口就叫系统调用。
从用户态到内核态切换可以通过三种方式:
- 系统调用,其实系统调用本身就是中断,但是软件中断,跟硬中断不同。
- 异常:如果当前进程运行在用户态,如果这个时候发生了异常事件,就会触发切换。例如:缺页异常。
- 外设中断:当外设完成用户的请求时,会向CPU发送中断信号。
 微信
微信 支付宝
支付宝




